

Finally Understanding the Data Availability
Finally Understanding the Data Availability
Prerequisite to Understand Celestia

Introduction
Why I started to learn Data Availability
If I have to choose the 3 most important topics in blockchain technology, It would be Interoperability, Data Availability and Scalability. Although these topics are all interesting, I dived in to data availability because of the Celestia. As many of smart people started to tweet about Celestia, I tried to learn about it. However, I failed because I had no clue what Data Availability was. It was then that my journey to Data Availability began.

Definition of Data Availability
Data Availability refers to whether the entire data of newly produced block is available to nodes.
Why does it matters
Then why does Data Availability matters? It’s because proper fraud proof can be done only when Data Availability is guaranteed.
Fraud Proof
Full node and Light node
There’s two type of nodes in blockchain. Full node downloads all the data in blockchain and verifies the validity of transaction itself. Therefore, there are certain requirement of hardware and storage to operate full node. However, as every node cannot satisfy these requirements, light nodes exists. Light nodes only downloads the block header, so they rely on full node for transaction verification.
At this point, how will light nodes detect whether new block contains invalid transaction?
If full node detect invalid transactions while verifying newly created block, it sends something called fraud proof to light node. Light node verifies this fraud proof and if it’s valid, it judges that current block contains invalid transaction and rejects the block.
When full node submits fraud proof of certain transaction, it needs the data of corresponding transaction.
Situation when Fraud Proof may not work
Fraud proof may fail in following situation.
Malicious block producer can hide and not publish certain data which contains the invalid transaction. Furthermore, he might only publish block header.
Now, as light nodes only download block header, it cannot know if invalid transaction is contained or not. Full nodes, because it downloads the entire data, it can detect the invalid transaction. However, it cannot submit the corresponding fraud proof to light node because the invalid transaction data is not published by block producer. So, because fraud proof is not submitted, light nodes may think that block is valid and invalid transaction will be contained in the blockchain.
Additionally, when fraction of data is not published to nodes, we cannot determine whether it’s intentional by block publisher or it’s due to systemic error like network delay. So. we get caught in dilemma where neither we can punish the block producer nor just leave it alone.
We call this situation as Data Availability Problem.
Data Availability Problem
Data Availability can be defined as following.
How can we be sure that every data of newly produced block is published to nodes?
or
How can we enforce block producer to publish all the data of newly produced block?
Wrong Solution
Simple, but wrong solution is to enforce all the light nodes to download the entire blockchain data. It would solve the problem, but It goes against the purpose of the light node in the first place.
Data Availability Proof
This is the answer that we are looking for. Data Availability Proof enables light nodes to only download some pieces of block data to verify whether entire block data is published to nodes.
Data Availability Proof
Erasure Coding
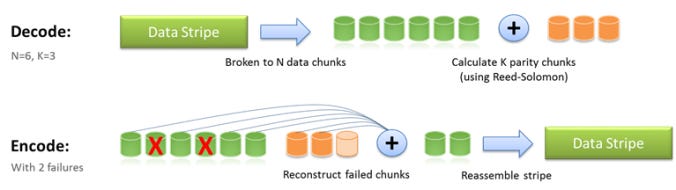
Erasure coding is mathematical scheme used in Data Availability Proof. The goal of erasure coding is although part of data is erased(lost), we can recover the original data with remaining ones. The most well-known erasure coding technique is the Reed-Solomon code.
We transform original length k data into length n. With subset of n chunks of data, we can recover the original data.
Simplest example of erasure coding
This is the special case when n = k+1. For example, let’s say that original data is “2 3 5 8” which is length 4. We transform this data into length 5 by adding the sum of original data, 18. At last, data becomes “2 3 5 8 18”.
After that, let’s say that we lost the second data, so data becomes “2 ? 5 8 18”. As we know that the last number is the sum of previous data, we can easily calculate that 3 is the missing data, which we just recovered the original data.
Slightly harder example of erasure coding
This is the special case when k = 2. For example, let’s say that original data is “2 3” which is length 2(k = 2). In this case, we can make a linear function f(x) that satisfies f(0)=2 and f(1)=3, where f(x)=x+2. We transform this data into length 4 by adding f(2), f(3) which is 4, 5. At last, data becomes “2 3 4 5”.
After that, let’s say that we lost the first and second data, so data becomes “? ? 4 5”. As we know the f(x), we can calculate the f(0) and f(1) to recover the original data.
Erasure coding in Data Availability Proof
For convenience, let’s assume that n = 2k. We first divide entire transaction data of block into k data chunks. Then, by erasure coding, we transform the original data into n data chunks. Merkle Root of these n data chunks are included in block header.
Because n = 2k, We only need at least k data chunks, which is 50% of data to recover the original data. This means that in order to prevent a malicious block producer from recovering the entire block, at least k+1 chunks, about 50% or more of data, should be hidden and not propagated.
Mechanism
First, block data is erasure coded and original data of length k transformed into data of length 2k. So, to recover the full block, nodes only need at least k data chunks. At this point, for malicious block producer to include specific invalid transaction inside the newly created block, he should hide at least k+1 data chunks. How will light nodes detect that this block is invalid without downloading full data? It works as follows.
First, light nodes randomly download some data chunk and if corresponding chunk is unavailable because malicious block producer has not published, light node judges that block is invalid and reject it. If the node download one data chunk every round, the odd that light node will detect the invalid block at first round will be 50%. With second rounds, odd becomes 75%, third rounds 87.5%, and eventually with 15 rounds the odd converges to 100%.
One last question
So we have learned how light nodes verify data availability without relying on full node and downloading the full data. However, there is still one problem left that we haven’t cover. How can we be sure that block data is erasure coded correctly? If, malicious block producer doesn’t implement erasure coding correctly, Data Availability Proof wouldn’t work.
Because full node downloads all the data, it can verify the validity of erasure coding by comparing the given erasure coded data and data that node erasure coded by itself. However, problem occurs for the light nodes because light nodes doesn’t download full data.
In conclusion, we can use multi-dimensional Reed-Solomon code to check the validity of erasure coding only with partial data. Although the detailed mechanism of Reed-Solomon code is beyond the scope of this article, long story short, 2D Reed-Solom code transforms the original data into 2-dimensional matrix.
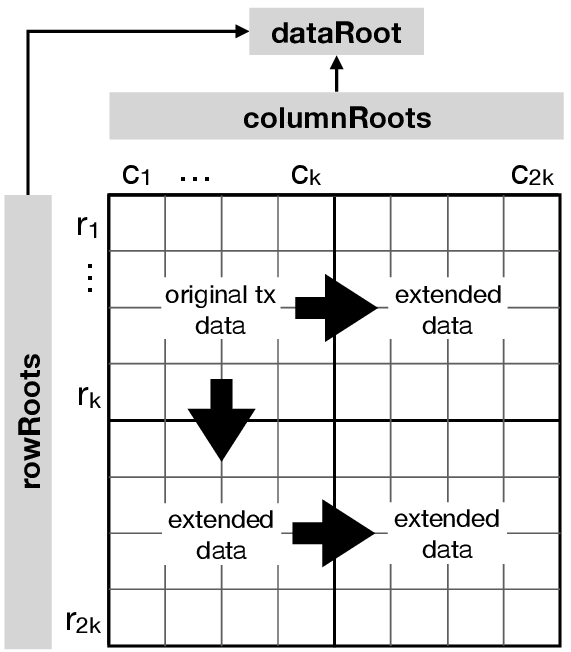
When we represent data into 2-dimensional, when the original data is length of k, each edge becomes length k^(1/2). So, to check if specific row or column is erasure coded correctly, we only need k^(1/2), not k.
From the point of complexity, original 1D Reed-Solomon code has O(n) time and storage complexity, but 2D Reed-Solomon code has O(n^(1/2)) when original data is length of n. However, multi dimensional Reed-Solomon code makes the entire erasure coded data much bigger.
Moreover,
If you got interested in Data Availability problem and curious about enormous details which is missing in this article, I strongly recommend you to check out following contents.
Original paper by Vitalik Buterin
Because this paper is the basis of Data Availability Problem, you can learn the A to Z of Data Availability from this paper. However, because its legit research paper, it’s long and complicated(at least for me).
1 to 1 lecture video based on above paper
This lecture is John Adler, CRO of Celestia explaining about Data Availability Problem to Alexander Skidanov, Co-founder of NEAR protocol. I recommend this video because it covers almost the same content as the above paper, but explains it with an easier example.
If you want to know more about Erasure Coding & Reed-Solomon code
While I dig into Data Availability Problem, erasure coding and Reed-Solomon code was the hardest part to understand.
Learning about Parity check is the easiest way to understand erasure coding. This video teaches Partiy check very easily. After, you may check this and this video, also. If you got the big picture of erasure coding, check out the wikepedia page because it gives two examples about erasure coding.
If you want to know exactly what Reed-Solomon code is, I recommend this video which I’m also studying.
Articles that I referred to